Pearl PoUW | Useful Work vs. Consensus
0. Start here — product, users, and mass adoption
One-liner: Pearl is a new proof-of-work cryptocurrency (PRL) whose mining puzzle looks like matrix multiplication. The optional “useful” part is running a special LLM inference stack on the same GPU. Nobody buys matmul. They buy coins, or (rarely) discounted API tokens.
Read next: What Pearl matmul actually means (not BF16/FP8 commodity inference) · API pricing vs OpenRouter · Fleet simulation
What is the product? (there are three, not one)
| # | Product | What you get | Who pays |
|---|---|---|---|
| A | PRL coin | Block rewards + speculative asset | Miners earn it; market buys/sells it |
| B | Mining software | pearld + vLLM Pearl plugin + gateway |
Miners (to compete for PRL) |
| C | Inference API (thin) | Normal LLM chat completions; Pearl checkpoint only | Developers via Together AI — ~25% off Together list, not vs OpenRouter |
Not a product today: training compute, generic matmul-as-a-service, marketplace GPU rentals (compute.pearlresearch.ai is gated), industry-standard FP8/BF16 stacks.
What transacts vs what runs under the hood
Product mapUser stories (four personas)
pearl-ai/gemma-4-31b-it like any LLM API. Doesn't know or care about matmul. Gets ~25% off because Together mines PRL on same GPUs.
Training or inference?
| Today (mainnet) | Pearl marketing / future | |
|---|---|---|
| Training | ❌ Not supported | Maybe after FP PoUW (whitepaper §1.1) |
| Inference | ✅ Only via Pearl quant models + plugin | Same, plus cheaper if subsidies grow |
| Bare mining (no AI) | ✅ Valid consensus path | Competes with “useful” story |
The world if everyone used Pearl
Today (~May 2026)
- Small miner fleet on H200 pods
- ~59k blocks, rewards dominate economics
- 1 commercial inference partner (Together)
- 3 pearl-ai models, 0 HF inference providers on Llama
- Mining works; AI marketplace doesn't exist yet
Pearl success world (their pitch)
- Every GPU datacenter runs Pearl plugin by default
- Inference/training revenue + PRL subsidy on same watt-hour
- PRL valuable → bigger subsidy → cheaper AI APIs
- On-chain compute marketplace matches buyers/sellers
- AI industry adopts Pearl quant path at scale
Mass-adoption flywheel (why they'd say it happens)
Bull caseThis only works if inference demand and PRL price move together. The chain does not enforce the left side of the loop.
Is mass adoption realistic?
AGTI realism check — what must go right
May 2026 assessmentPearl int7/8-bit plugin ≠ OpenRouter BF16/FP8 Gemma — different weights, Hopper-only, 3 models. Details §7
Why mass adoption might happen (bull case):
- PRL price pumps → mining subsidy exceeds inference margin → every GPU farm installs Pearl plugin “for free money.”
- More cloud APIs copy Together → discounted inference pulls developers into Pearl quant models.
- FP PoUW ships → training clusters join → “useful work” expands beyond inference.
Why it might not (bear case — AGTI default):
- Protocol allows bare mining — farms skip LLM entirely once subsidies are high enough (whitepaper admits this).
- Not commodity matmul — industry runs BF16/FP8
google/*on stock vLLM; Pearl requirespearl-ai/*-pearl, int7 NoisyGEMM, sm90 Hopper, and most layers/dims never mine (§7). - Circular economics — Together discount depends on PRL emissions; if coin is weak, subsidy vanishes.
- Training never arrives — without it, “AI-native PoW” is really “inference-miner PoW.”
- Bitcoin dynamics repeat — specialization wins; dual-use hobbyist GPUs lose to dedicated matmul lottery farms.
AGTI plain answer: The product that exists today is PRL + miner software, with one subsidized inference API as a proof-of-concept. Mass adoption is not unrealistic for the coin/mining layer (another PoW chain can absolutely attract hashrate). It is unrealistic as stated for “the AI industry runs on Pearl matmul” unless Pearl quant becomes a standard, PRL stays valuable, and inference demand genuinely co-locates with mining — none of which is proven yet.
1. The tension in one glance
Pearl’s whitepaper sells 2-for-1 GPU economics: security subsidy plus useful AI output from the same watt-hours. The open-source reference miner grinds random matrices until a BLAKE3 jackpot clears difficulty — no LLM, no user, no tokens.
Bitcoin PoW vs Pearl PoW — what silicon actually does
Stack comparisonPearl swaps SHA256 for matmul+ZK. Without the optional vLLM box, the waste structure mirrors Bitcoin — only the opcode changed.
2. Whitepaper promise vs chain rules
Marketing layer
- Mining native to AI MatMul
- 2-for-1 GPU cycles (security + inference)
- Virtuous loop: demand → subsidy → compute → security
- Drop-in plugin, negligible overhead
- Future compute marketplace
Consensus layer
- Valid ZK-PoW certificate required
- Random / committed matrices OK
- No inference API check
- No "tokens served" field
- Bare
mine()loop is valid
Where the whitepaper forks from the protocol
Economic vs enforcedThe dashed line is a deployment choice (vLLM). The protocol path works without ever serving a user.
The whitepaper also admits: “Pearl attracts compute that does not necessarily have useful work.”
3. How Pearl mining works (PoUW pipeline)
From matrices to block — the lottery inside the multiply
Protocol flowCode anchors: bare search in zk-pow/src/ffi/mine.rs · defaults in node/zkpow/miner.go (k=1024, rank=32) · verify in node/zkpow/verify.go.
4. Two miners, one protocol
Coherent vs nonsensical — same consensus, different economics
Miner comparisonProduction: vLLM miner
- Matrices = weights + activations
- 7-bit layers → NoisyGEMM
- 8-bit layers → vanilla GEMM
- Output: LLM tokens + block candidates
- Hardware: H100 / H200 (sm90)
Bare / ASIC: zk-pow only
- Matrices = lottery inputs
- Same jackpot + ZK machinery
- No model, no API, no users
- Output: block rewards only
- Hardware: matmul+zk silicon
Both paths can win blocks. Only the vLLM path delivers Pearl's stated utility.
5. ASIC economics — when dual-use wins
The whitepaper’s ASIC argument is profitability, not impossibility: a Pearl-only chip “will lose the ability to do useful work, and thereby be overall less profitable.”
Who wins the hardware game?
Equilibrium mapLow subsidy · High inference
GPU farms serve APIs. Mining is opportunistic side income. Pearl's happy path.
High subsidy · High inference
Best of both worlds — if overhead stays negligible. Whitepaper virtuous loop.
Low subsidy · Low inference
Niche hobbyist mining. Chain stays weak. Uninteresting equilibrium.
High subsidy · Low inference
ASIC / bare farm zone. Matmul lottery dominates. Mission collapses.
Compute budget — where the joules go
Conceptual energy splitIllustrative split, not measured mainnet telemetry. Shows why bare mining recenters waste in the PoW bucket.
6. Fleet dynamics simulation (AGTI model)
The quadrant map above is qualitative. To stress-test when dual-use wins vs ASIC/bare farms, AGTI built a monthly fleet dynamics model in Python/numpy: three fleet types (dual-use GPU, bare GPU, ASIC) compete on hashrate share, revenue, and profit-driven capacity growth.
Question: If PRL subsidies rise, inference demand stays flat, and ASIC hash/$ improves, does the network stay on the useful-work path — or converge to matmul lottery farms? Source: AGTI fleet simulation (simulate.py). Parameters are illustrative, not calibrated to mainnet.
Model mechanics (monthly loop)
simulate.pyhash × 0.82 + inference margin] B[Bare GPU
hash × 1.12, mining only] A[ASIC
hash × 3.5–14×, mining only] end subgraph month ["Each month"] H[Total hashrate → share split] R[Mining revenue ∝ share × blocks × PRL] I[Inference revenue — dual only, demand-capped] C[Electricity + capex amort + opex] P[Profit margin → grow/shrink capacity] X[PRL mean-reverts to production cost] end D --> H B --> H A --> H H --> R --> P I --> P C --> P P --> D P --> B P --> A P --> X style fleets fill:#0d2818,stroke:#6ee58f,color:#e8eeeb style month fill:#1a1210,stroke:#ff5a42,color:#e8eeeb
Useful-work proxy: fraction of hashrate from dual-use fleets (serves inference + mining). Not enforced by Pearl consensus — this is the mission metric. Concentration: Herfindahl–Hirschman Index (HHI) on hashrate shares.
| Scenario | Stress | Month 36: useful hash | ASIC share | Inference % revenue | HHI |
|---|---|---|---|---|---|
baseline |
Moderate PRL ($0.05), 400 GPU demand | 0.3% | 99.7% | 1.1% | 0.995 |
prl_pump |
PRL ramps to ~$0.75; flat demand | 0.7% | 95.6% | 0.5% | 0.916 |
inference_boom |
Demand → 4k GPUs; flat PRL | 11.5% | 88.5% | 45.0% | 0.796 |
asic_creep |
ASIC hash/$ → 4× | 0.1% | 99.9% | 0.2% | 0.999 |
together_only |
50 GPU demand (today-shaped) | 0.2% | 99.6% | 1.3% | 0.992 |
bitcoinification |
PRL pump + ASIC creep + flat inference | 0.1% | 99.7% | 0.4% | 0.995 |
Scenario charts — 36-month horizon
AGTI simulationbaseline
moderate PRL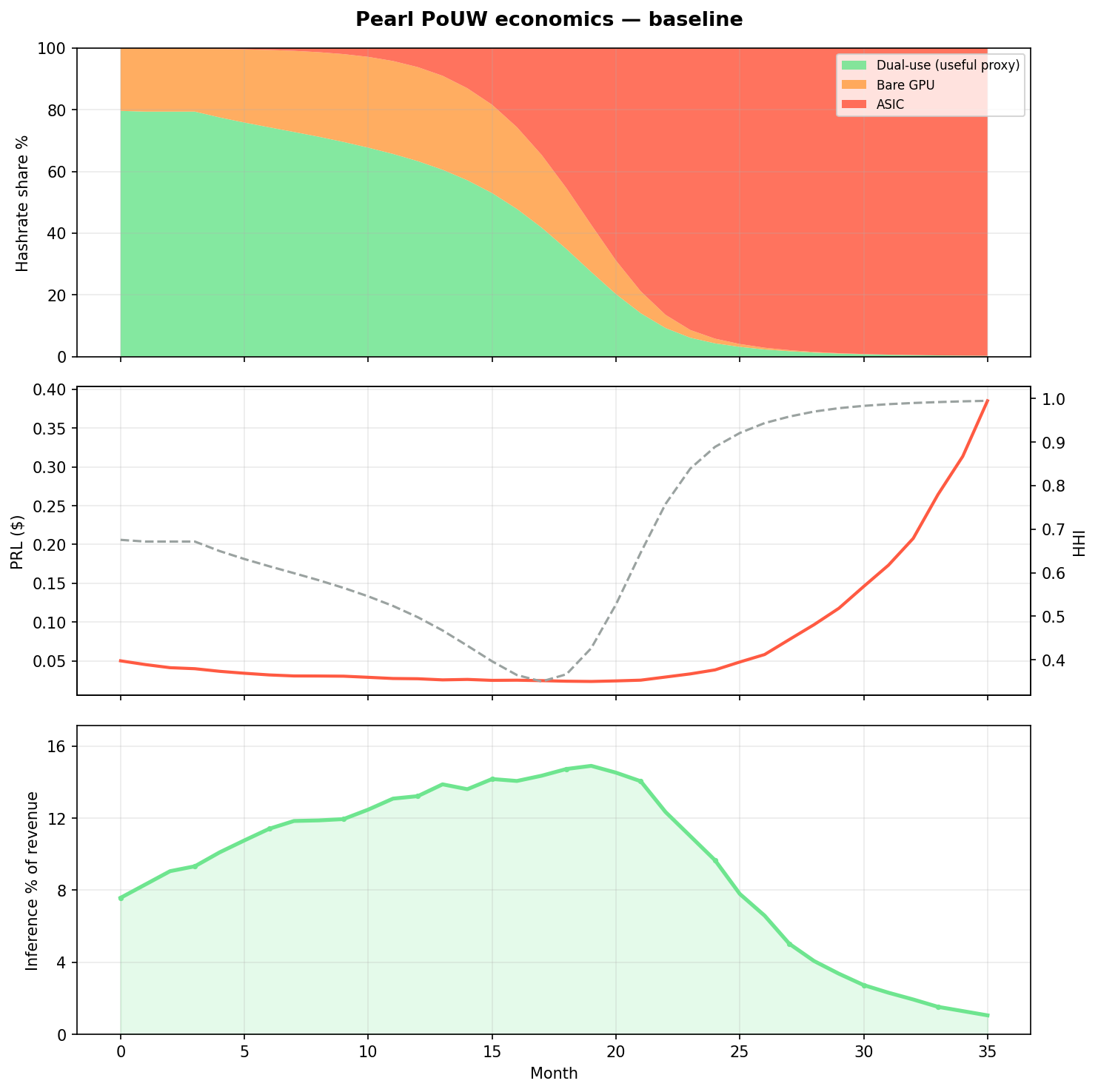
Endogenous PRL mean-reversion cannot stop ASIC crowding once hash/$ advantage compounds.
inference_boom
best case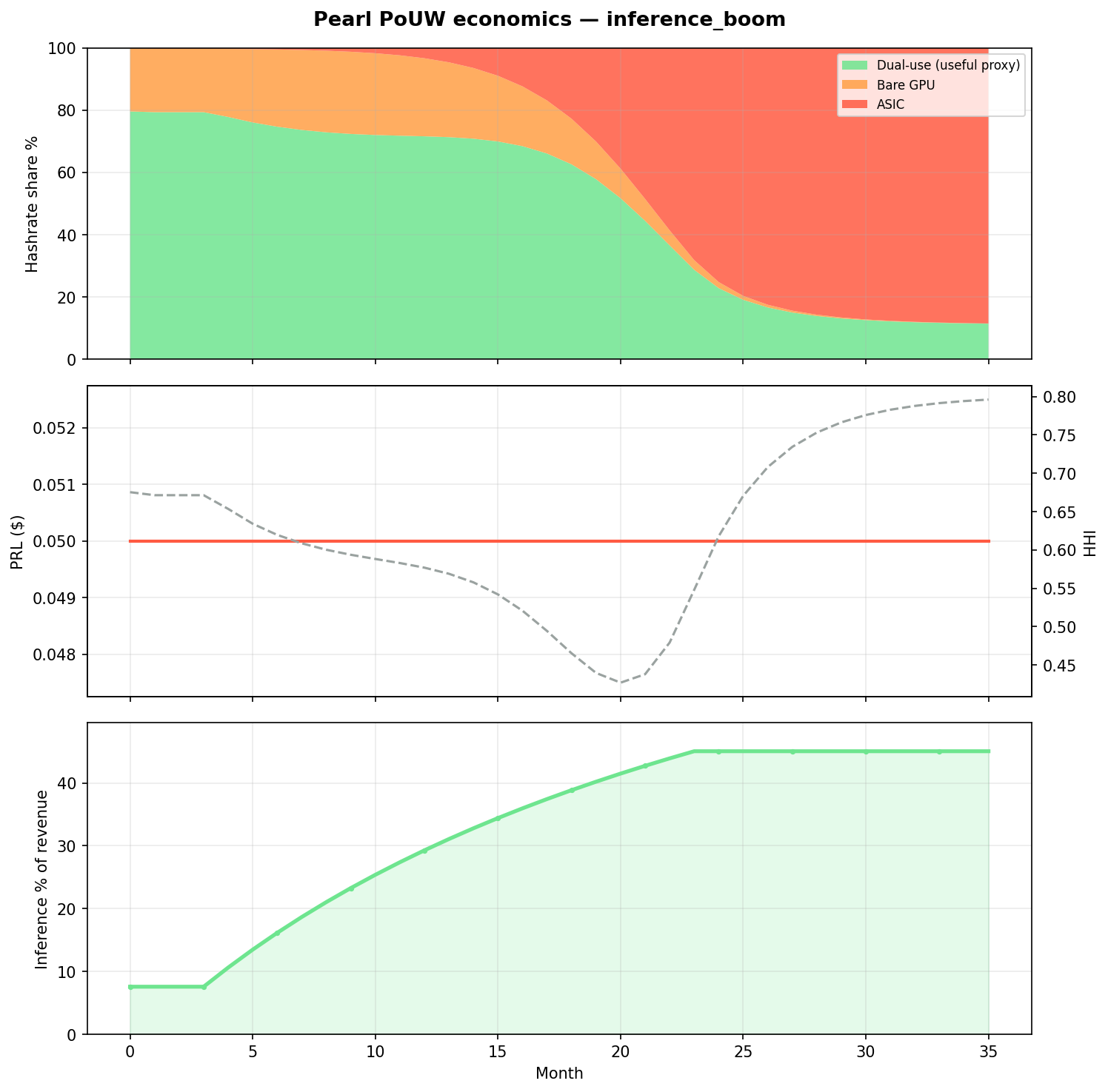
Only scenario where dual-use hashrate stays double-digit and inference becomes ~half of network revenue.
prl_pump
subsidy shock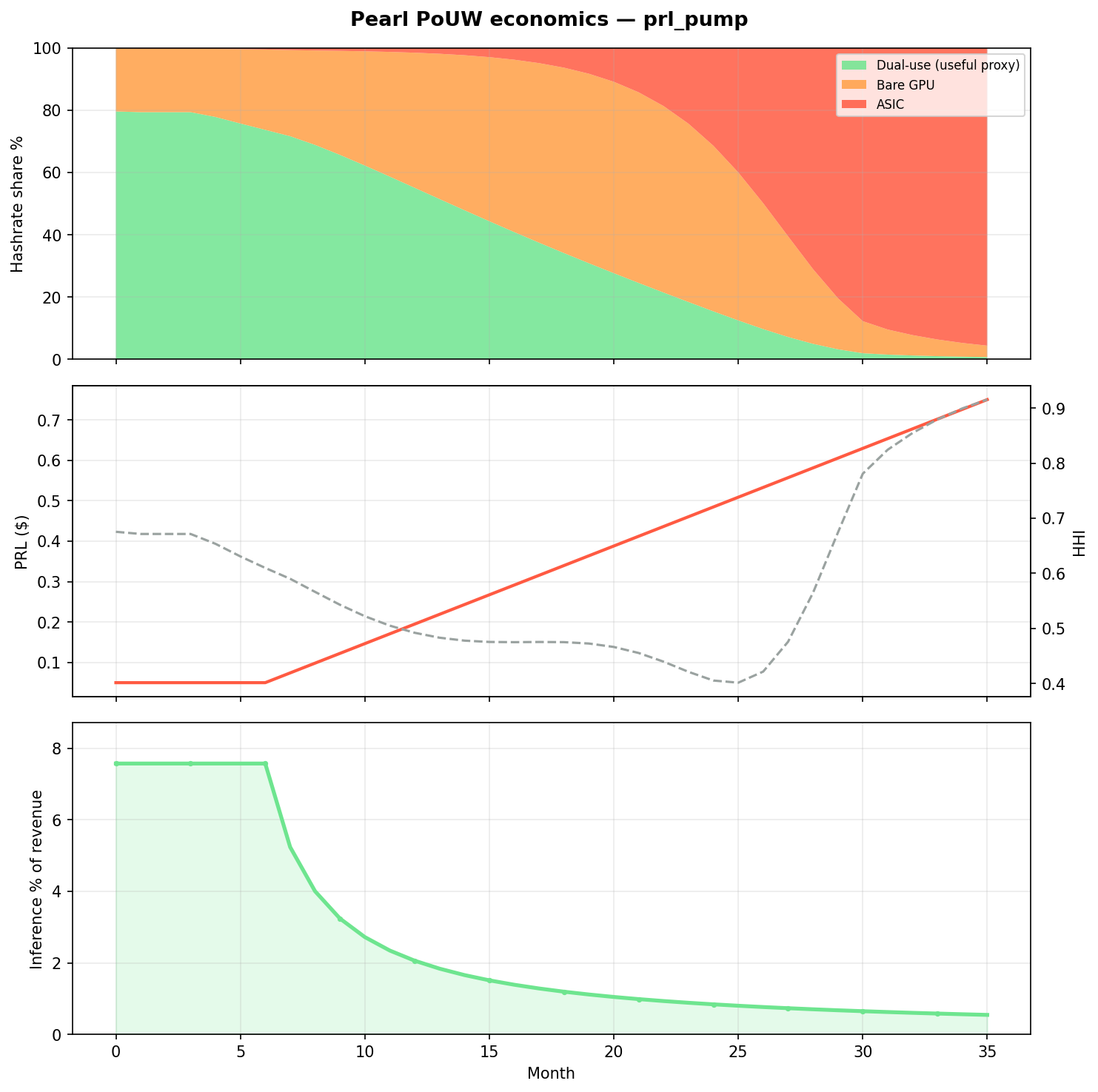
Higher PRL alone attracts capital into best hash/$ — ASICs and bare GPUs, not vLLM farms.
asic_creep
hardware curve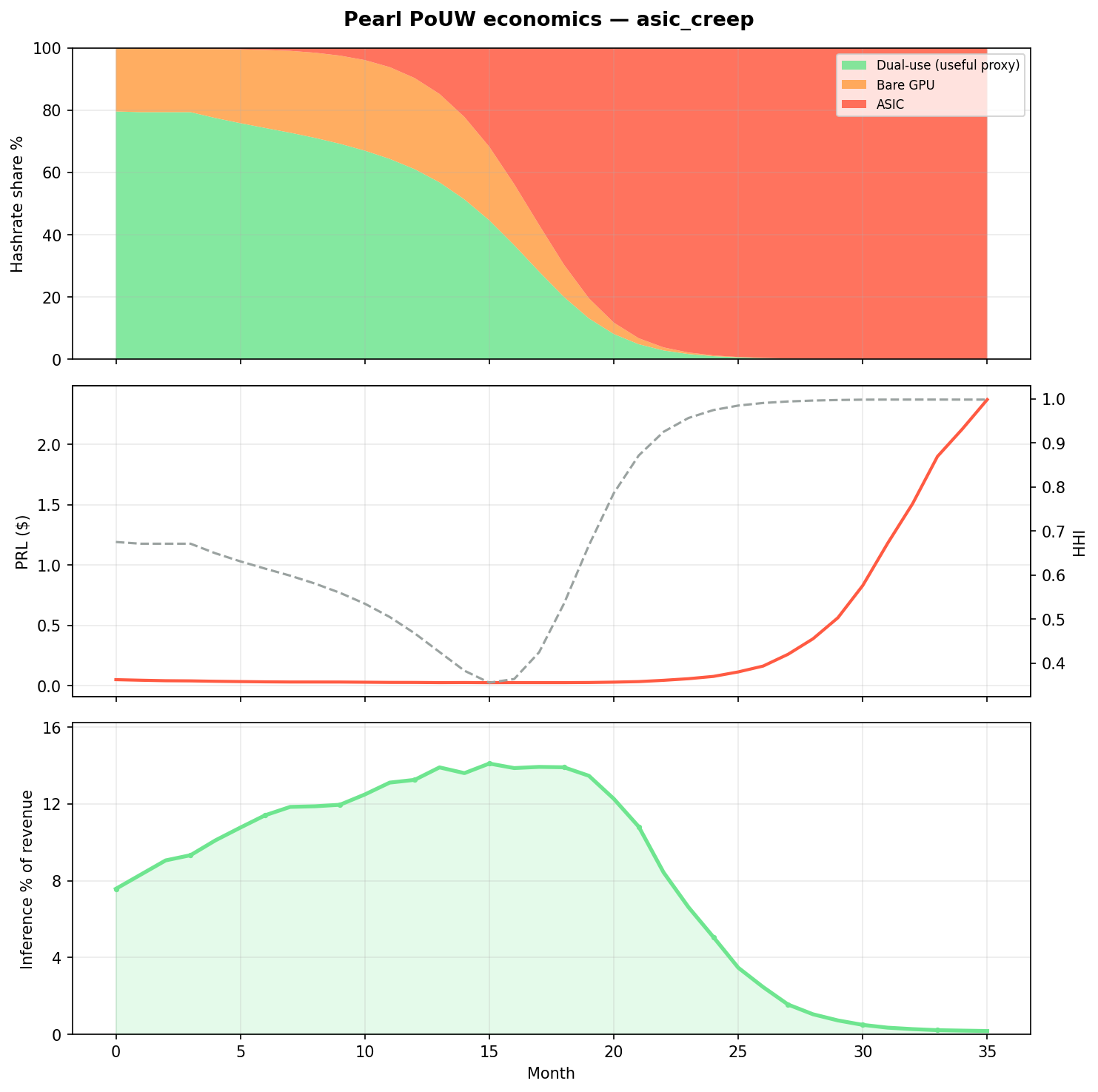
4× ASIC efficiency gain → HHI ≈ 1.0. Matches whitepaper's "compute without useful work" branch.
together_only
May 2026 shaped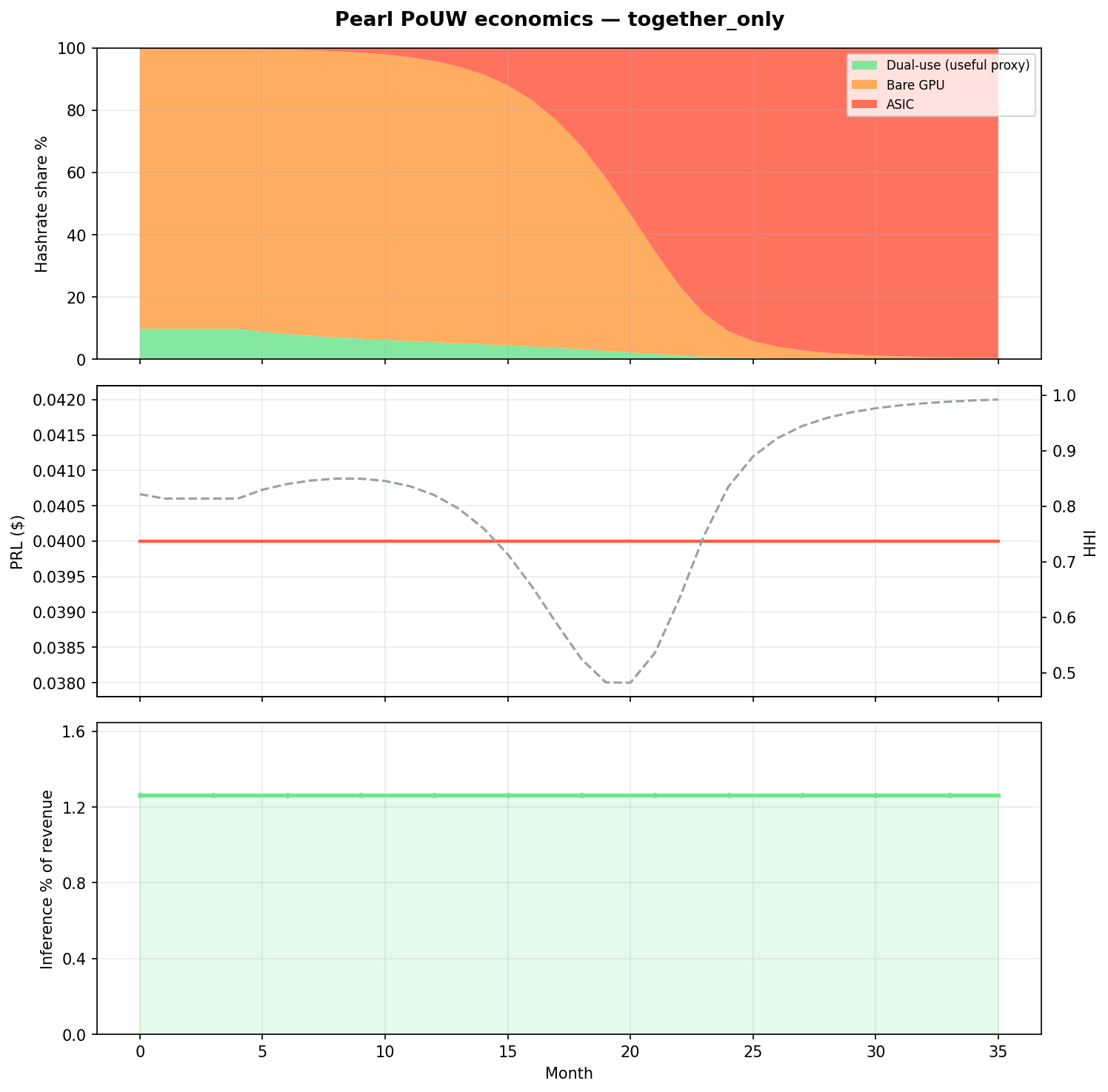
Tiny API demand (~50 GPUs) + low PRL: dual-use starts weak and terminal useful hash → 0.2%.
bitcoinification
stress test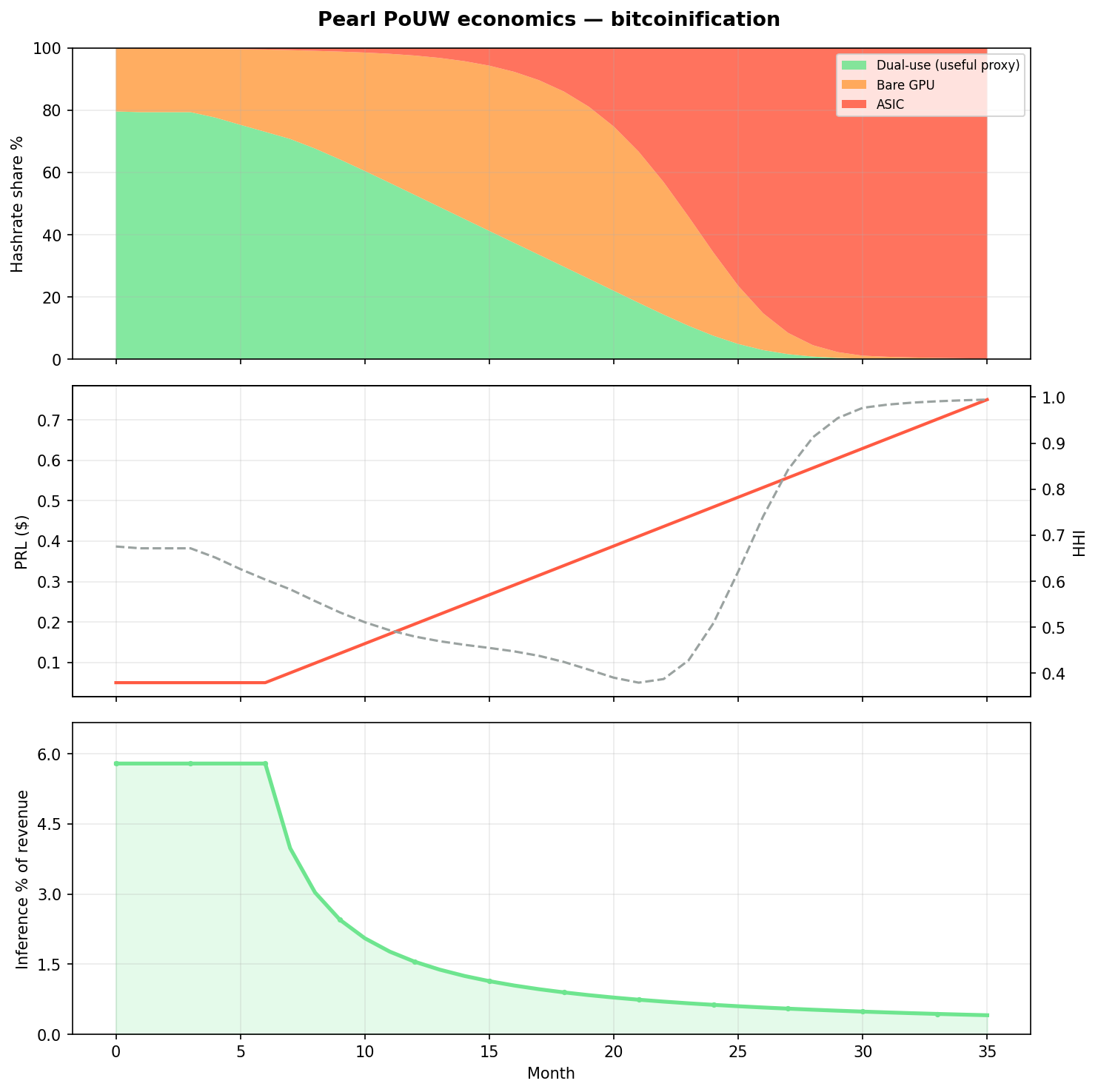
Combined pump + ASIC creep + flat inference — mission collapse. Structurally Bitcoin-shaped.
AGTI read from the sim: PRL price alone does not preserve useful work. The whitepaper virtuous loop (§8 below) requires inference demand scaling with subsidies — the only lever that materially keeps dual-use competitive in this model. Today’s adoption profile maps closest to together_only.
Code anchors (reproducible)
Run locally (scripts hosted on AGTI — no repo clone required):
mkdir pearl-economics && cd pearl-economics
curl -LO https://agtico.github.io/assets/research/pearl-economics/requirements.txt
curl -LO https://agtico.github.io/assets/research/pearl-economics/simulate.py
curl -LO https://agtico.github.io/assets/research/pearl-economics/compare_inference_pricing.py
python3 -m venv .venv && .venv/bin/pip install -r requirements.txt
.venv/bin/python simulate.py --all --plot
.venv/bin/python compare_inference_pricing.py
Full folder: agtico.github.io/assets/research/pearl-economics/
Limits: Not calibrated to Pearl mainnet difficulty (~4.9M), block reward decay, pool variance, or token sell pressure. ASIC is modeled as zero inference utility by definition (protocol allows it). See the research README.
7. Adoption & useful-work reality check
Pearl’s pitch treats “matmul” as if the AI industry already runs it. It doesn’t. When Google ships Gemma 4 31B, the ecosystem runs BF16/FP8 weights through stock vLLM, TensorRT, llama.cpp, SGLang — thousands of hosts, hundreds of billions of tokens/week on aggregators like OpenRouter. Pearl’s stack is a parallel, incompatible matmul pipeline: proprietary 7-bit/8-bit integer paths, NoisyGEMM crypto noise, Blake3 + Plonky2 proofs, and a Pearl-only vLLM plugin — today on three pearl-ai/* checkpoints and Hopper (sm90) GPUs only.
Plain English: Pearl did not turn “GPU matmul” into a commodity. They built a specialized lottery algebra that resembles linear layers inside one forked inference stack. Most layers in a Pearl model never mine. Most matrix sizes never mine. Standard BF16 Gemma on normal vLLM cannot produce valid Pearl blocks even if you point it at the same GPU.
What Pearl matmul actually means (three stacks)
Pearl conflates three different workloads under one brand. Only the first is what pearld validates; the second is optional dual-use inference; the third is inference-only inside the plugin.
| Stack | Precision / kernel | What it does | Required to mine? |
|---|---|---|---|
① Consensus (zk-pow) |
int7×int7→int32 tiles, values in [-64, 64], low-rank noise, Blake3 jackpot, Plonky2 STARK | Block lottery — verifies a noisy matmul transcript, not token quality | Yes — this is all pearld checks |
| ② NoisyGEMM (vLLM plugin) | 7-bit quant on selected layers; CUTLASS Hopper kernels add commitment + noise + inner-hash PoW extraction | Runs during LLM forward pass on large layers | No — deployment choice; only if layer + dims qualify |
| ③ Vanilla Pearl GEMM | 8-bit quant, standard scaled int8 GEMM, no noise / hash | Normal inference layers + small 7-bit matmuls | No — zero PoW on chain |
From LLM forward pass to block — where mining actually happens
Plugin routingand mining on?"} NOISY["NoisyGEMM
commit + noise + inner hash"] VAN["Vanilla pearl GEMM
inference only"] L7 --> TH TH -->|yes| NOISY TH -->|no| VAN L8 --> VAN end subgraph chain ["pearld consensus"] PP["PlainProof: int7 strips + Merkle"] ZK["Plonky2 verify + difficulty"] PP --> ZK end NOISY -.->|optional block submit| PP VAN --> OUT["bf16/fp16 tokens out
no block"] style vllm fill:#0d2818,stroke:#6ee58f,color:#e8eeeb style chain fill:#1a1210,stroke:#ff5a42,color:#e8eeeb
Source: Pearl vllm_kernels.py, config.yaml, zk-pow/verify. Inference can succeed while producing no valid blocks.
Mainstream AI matmul vs Pearl matmul
| Dimension | Industry default (Gemma 4 31B today) | Pearl stack |
|---|---|---|
| Weights | Google google/gemma-4-31b-it BF16/FP8 checkpoints |
pearl-ai/*-pearl re-quantized artifacts (HF org) |
| Runtime | Stock vLLM, TensorRT, NIM, llama.cpp, OpenRouter backends | Pearl vLLM plugin + pearl-gemm CUDA + pearl-gateway + pearld |
| Linear ops | FP16/BF16/FP8/FP4 tensor cores as provider chooses | int7 mining + int8 non-mining only; output activations back to bf16/fp16 |
| Mining | None | NoisyGEMM on subset of layers and only when m,n,k ≥ 1024 |
| Chain proof | N/A | int7 noisy transcript + jackpot hash — not “we served tokens” |
| GPU gen | A100–Blackwell, consumer GPUs with quant | sm90 Hopper only (H100/H200) per Pearl build |
| Model count | One base model → dozens of hosts | 3 public Pearl checkpoints (May 2026) |
OpenJarvis model enablement docs state explicitly: raw Hugging Face models like google/gemma-4-31b-it are not mineable — you need pearl-ai/Gemma-4-31B-it-pearl with quantization_config.quant_method = "pearl", mining layers tagged for 7-bit NoisyGEMM and attention/MLP down-proj kept on 8-bit vanilla paths.
Layer selection rules (why most matmul never mines)
Model config — a layer is a “mining layer” only if weights and activations are 7-bit, static channel/tensor weights, dynamic per-token activations, symmetric quant (vllm_config.py):
Runtime thresholds — even on 7-bit mining layers, NoisyGEMM (PoW path) runs only when all of m, n, k are ≥ 1024 (config.yaml). Smaller matmuls (typical of many attention/MLP shapes in a single forward step) fall back to vanilla GEMM → inference OK, no mining.
Consensus — separately, pearld only accepts Int7×Int7→Int32 MMA with strip values in [-64, 64], independent of whether anyone ran an LLM (verify.rs / proof.rs). The whitepaper’s “arbitrary matmul” is this fixed lottery format, not PyTorch torch.matmul generically.
What breaks if you use standard BF16/FP8 vLLM
| You try… | Result |
|---|---|
Run google/gemma-4-31b-it on stock vLLM + mine |
No Pearl blocks — no int7 strips, no noise transcript, no PlainProof |
Run pearl-ai/*-pearl without Pearl plugin |
Cutlass/default kernels — no NoisyGEMM, no gateway integration |
Use Pearl plugin but MINER_NO_MINING=true / small dims |
Inference works; hashrate = 0 |
| Run on A100 / L40 / consumer GPU | pearl-gemm builds for sm_90a only — won’t compile/run Pearl kernels |
| Assume Pearl matmul = commodity cloud matmul | Wrong product category — different weights, quant, context, behavior |
Pearl’s HF model card notes plain vLLM works for inference-only (no mining). Mining requires the full Docker stack: pearld + gateway + plugin-enabled vLLM.
Hardware & precision moat (May 2026)
- GPU: Pearl
pearl-gemmcompiles witharch=compute_90a,code=sm_90a— Hopper H100/H200 (setup.py). - Precision: Pearl whitepaper §1.1 states today’s protocol is exact INT matmul; FP/quantized PoUW for modern BF16/FP8 inference is a future upgrade — not what mainnet verifies today.
- Ecosystem: Google’s Gemma 4 launch targets BF16 on 80GB H100 and quantized variants on workstation GPUs via standard runtimes (Google announcement coverage) — a completely different supply chain from Pearl’s int7 plugin.
AGTI read: Pearl matmul is not fungible with industry matmul. Adopting Pearl means adopting Pearl-quantized models, Hopper-only kernels, and accepting divergent behavior vs the commodity google/* endpoints developers already use. That is why “the AI industry runs on Pearl matmul” is misleading — the industry runs BF16/FP8; Pearl runs a sidecar int lottery on a tiny model list.
Inference API pricing — subsidized vs market?
Together markets pearl-ai/gemma-4-31b-it at ~25% off, subsidized by Pearl mining. AGTI queried public catalogs May 24, 2026 (OpenRouter models API, OpenRouter endpoints, Together model pages).
Same name on the tin — not the same product
Not a commodity switchOpenRouter $0.12 / $0.37 per 1M"] M2["Google weights · FP4/FP8
262K context · multimodal"] M3["~295B tokens/week on OR"] end subgraph pearl_api ["Pearl Together endpoint"] P1["pearl-ai/gemma-4-31b-it
$0.28 / $0.86 per 1M"] P2["Pearl re-quant checkpoint · INT8
32K context · Pearl plugin stack"] P3["No pearl-ai slug on OpenRouter"] end M1 -. "not interchangeable" .- P1 M2 -. different weights/q/cap .- P2 style market fill:#0d2818,stroke:#6ee58f,color:#e8eeeb style pearl_api fill:#1a1210,stroke:#ff5a42,color:#e8eeeb
Switching from OpenRouter Gemma to Pearl Gemma is not a drop-in price arbitrage — different model artifact, quantization, context, and stack. Benchmarks and tool schemas may diverge.
| Offering | API slug | Input $/M | Output $/M | Context | Notes |
|---|---|---|---|---|---|
| OpenRouter (router default) | google/gemma-4-31b-it |
$0.12 | $0.37 | 262K | Usually routes to DeepInfra-class providers |
| OpenRouter → Together (Pearl stack) | google/gemma-4-31b-it |
$0.28 | $0.86 | 32K | Same $/M as Pearl endpoint; one of the most expensive OR backends |
| Together standard Gemma | google/gemma-4-31B-it |
$0.39 | $0.97 | 256K | FP8, full context — Together’s list price |
| Together Pearl Gemma | pearl-ai/gemma-4-31b-it |
$0.28 | $0.86 | 32K | Pearl checkpoint + INT8; marketed ~25% off Together list |
Blended example (1M input + 200k output tokens): OpenRouter best ≈ $0.19 · Together Pearl ≈ $0.45 → Pearl is ~2.3× more expensive than where Gemma 4 31B actually trades volume today.
AGTI read:
- The discount is internal. Pearl is ~23% below Together’s own $0.39/$0.97 SKU — that’s the “~25% off” claim. It is not below OpenRouter’s $0.12/$0.37 market.
- Subsidy isn’t showing up as market undercut. If PoUW + PRL emissions were funding cheap inference, Together’s Pearl route should compete on absolute price. Instead OpenRouter routes away from Together to cheaper hosts.
- Not commodity Gemma.
pearl-ai/gemma-4-31b-itis a Pearl re-quantized checkpoint (HF:pearl-ai/Gemma-4-31B-it-pearl), not Google’s base weights. INT8 vs FP8, 32K vs 262K context, Pearl vLLM plugin required. Developers cannot treat it as a fungible swap forgoogle/gemma-4-31b-iton OpenRouter — quality, latency, and behavior are questionable to assume equivalent. - No separate OpenRouter listing. There is no
pearl-ai/*slug on OpenRouter. Pearl only appears as Together’s 32K / $0.28 / $0.86 backend when the router hits that provider.
Reproduce pricing check: compare_inference_pricing.py (public APIs, no keys).
Three different things called "matmul"
Compatibility mapSources: whitepaper §1.1, pearl-ai HF org, Together endpoint, explorer.
On-chain signals vs inference demand
May 2026 snapshotpearl-ai/gemma-4-31b-it at 25% discount
1 partner
Marketing claim vs observed evidence
Useful work auditWhitepaper quote: "Pearl attracts compute that does not necessarily have useful work." — pearlresearch.ai §1. "Useful MADs" = matmul ops hashed for mining (HF benchmark table), not MADs sold downstream.
| Question | Factual answer (sourced) |
|---|---|
| Who uses Pearl matmul? | Pearl Labs, GPU miners, Together AI (Gemma endpoint only) |
| Do HF downloads = users? | No — likely miner weight pulls; 0 inference providers on Llama-pearl |
| Does mainnet = utility? | No — proves mining; ~2.7k PRL/block is subsidy, not API revenue |
| Is useful work enforced? | No — whitepaper admits non-useful compute; bare mine() valid |
| Is Pearl API cheaper than market Gemma? | No — ~2.3× above OpenRouter $0.12/$0.37; discount is vs Together list only |
| Is Pearl matmul = industry matmul? | No — int7/8-bit plugin stack vs BF16/FP8; Hopper-only; 3 models |
| Can I swap google/gemma for pearl-ai? | No — different checkpoint, quant, context; model migration not price toggle |
| Strongest dual-use case | Together × Pearl — volume not public |
AGTI read: Useful work is weakly evidenced and narrowly compatible. The chain proves matmul lottery tickets; the one external API is not market-competitive on price and not interchangeable with commodity Gemma 4 31B on OpenRouter.
8. Whitepaper virtuous loop vs reality
9. Verdict & due diligence
| Question | Answer |
|---|---|
| Technically serious? | Yes — full node, zk-pow, CUDA, vLLM plugin |
| ASIC feasible? | Yes — GEMM + BLAKE3 + ZK are acceleratable |
| ASIC useful? | No — secures chain, produces no AI product |
| Useful work evidenced? | Thin — 1 Together endpoint; HF downloads ≠ demand |
| Industry adopted matmul? | No — int7/8-bit Pearl plugin on Hopper only; not fungible with BF16/FP8 google/gemma-4-31b-it |
| Pearl API competitive? | No — ~2.3× above OpenRouter Gemma pricing; pearl-ai/* is a different checkpoint |
| Mass-adoption matmul thesis? | Weak — parallel supply chain (3 models), not industry standard |
Evaluators should track:
- Share of hashrate on vLLM vs bare clients (see §6 simulation)
- Whether Pearl API prices undercut OpenRouter commodity Gemma (today: no — §7 pricing)
- Whether developers adopt
pearl-ai/*vs staying ongoogle/*(model migration, not swap) - ZK proving cost vs search cost at target difficulty
- Together endpoint traffic + HF inference provider count on pearl-ai models
Full source doc with code citations: agti/docs/pearl_pouw_useful_work_asic_analysis_2026-05-23.md
Disclaimer: Independent AGTI research for informational purposes only. Not investment advice.